Key To Nature - mehr als Nahrungsergänzung
Der Schlüssel zu einem gesunden Leben!
Über Key To Nature
Key To Nature ist deine zentrale Anlaufstelle für ehrliche, unparteiische und zuverlässige Bewertungen von natürlichen Nahrungsergänzungsmitteln.
Die Vielfalt der Nahrungsergänzungsmittel auf dem Markt ist groß, verwirrend und unübersichtlich. Da kann es schwierig sein, dass passende Produkt zu finden.
Bei Key To Nature nehmen dir unsere Experten die Recherche-Arbeit ab, indem sie verfügbare Nahrungsergänzungsmittel durchsehen und dir helfen, jedes Produkt, sowie seine Vorteile und Nachteile zu verstehen.
Wir testen jedes Produkt und verfassen ausführliche Berichte über Hersteller, Inhaltsstoffe, Vorteile, mögliche Nebenwirkungen und Kosten jedes Produkts. Außerdem empfehlen wir dir nur Produkte, die auch wirklich Wirkung zeigen – alles wissenschaftlich belegt!
Hierfür durchforsten wir das Netz nach Studien, wissenschaftlichen Veröffentlichungen und auch Produktbewertungen von Kunden, die selbst Erfahrungen mit der Marke oder dem Produkt gemacht haben.
Wir helfen dir bei Key To Nature zu einem gesunden Leben und unterstützen dich, bei der Verwirklichung deines Traumkörpers.
Die beliebtesten Beiträge

Unsere Vorgehensweise Unglücklicherweise haben Männer jeden Alters mit erektiler Dysfunktion zu kämpfen. Dabei haben die Probleme unterschiedliche Gründe: Vitalität, Angstzustände und körperliche Gesundheitsprobleme können sich negativ auf die Leistungsfähigkeit im Bett auswirken. Bis jetzt war die einzige verfügbare Lösung die „kleine blaue Pille“, die leider oft mehr Schaden anrichtet, als dass sie wirklich nutzt. Außerdem […]

Unsere Vorgehensweise Leider ist der Großteil der Diätpillen des Marktes alles andere als hilfreich und zu derselben Zeit auch äußerst schädlich für die Gesundheit, weshalb sich viele Menschen die Frage stellen, welchen Diätpillen sie bezüglich der Verträglichkeit und der Wirkungsweise trauen können? Eine Pille, welche in diesem Zusammenhang immer öfter ins Gespräch kommt, ist PhenQ. […]
Unsere Vorgehensweise Viele Männer sind mit der Länge und auch mit dem Umfang ihres Penis unzufrieden und würden gerne etwas daran ändern. Aus diesem Grund sehen sich sehr viele Männer nach Mitteln und Möglichkeiten um, welche die unterschiedlichen Anbieter auf dem Markt zur Verfügung stellen, um ihren zu kleinen Penis sowohl in der Länge als […]

Unsere Vorgehensweise Es ist vollkommen natürlich und in dem biologischen Rhythmus des männlichen Organismus vorgesehen, dass der Körper ab einem Alter von circa 40 Jahren die Produktion des wichtigen, männlichen Sexualhormons Testosteron deutlich herunterfährt. Je mehr der Testosteron-Spiegel im männlichen Körper sinkt, umso präsenter werden in der Regel die Beschwerden, mit welchen die Betroffenen in […]

Unsere Vorgehensweise Obwohl sich viele Menschen mit ihrem Gewicht unwohl fühlen, treffen die Meisten unter ihnen auf Probleme, wenn es um die Gewichtsabnahme geht. Viele fühlen sich nicht bereit dazu, Gewohnheiten umzustellen oder etwas mehr körperliche Betätigung in ihren Alltag zu integrieren. Das führt auf die Dauer dazu, dass die Kilos nicht nur nicht schmelzen, […]

Unsere Vorgehensweise Da viele Menschen mit ihrem Gewicht unzufrieden sind und sich in ihrer eigenen Haut nicht mehr wirklich wohlfühlen, erfreut sich der Markt der Produkte, die Menschen bei der Abnahme unterstützen können sollen, einer sehr großen Beliebtheit. Immer mehr Menschen sehen sich aufgrund von Zeitmangel oder auch wegen der mangelnden Motivation nach Produkten um, […]

Unsere Vorgehensweise Um an Gewicht verlieren zu können, stehen Menschen in der heutigen Zeit sehr viele unterschiedliche Diäten zur Auswahl, aus welchen sie wählen können. Unter den vielen unterschiedlichen Ernährungsformen, die auf ihre ganz eigene Weise bei der Gewichtsabnahme helfen können sollen, befindet sich die Keto-Diät oder, wie sie auch genannt wird: Die Keto Ernährung. […]
Unsere Vorgehensweise Unglücklicherweise haben Männer jeden Alters mit erektiler Dysfunktion zu kämpfen. Dabei haben die Probleme unterschiedliche Gründe: Vitalität, Angstzustände und körperliche Gesundheitsprobleme können sich negativ auf die Leistungsfähigkeit im Bett auswirken. Bis jetzt war die einzige verfügbare Lösung die „kleine blaue Pille“, die leider oft mehr Schaden anrichtet, als dass sie wirklich nutzt. Außerdem […]

Unsere Vorgehensweise Wenn es im Bett nicht mehr so läuft, man keine Lust mehr auf Sex hat oder das männliche Glied schlicht und ergreifend nicht mehr mitmacht oder Erektionen nur sehr kurz halten, hat das nicht nur einen Einfluss auf den Mann, sondern auch auf die Beziehung. Sehr viele Männer schämen sich für ihr Problem, […]

Unsere Vorgehensweise Das Sexleben eines Mannes und folglich eines Paares kann unter vielen unterschiedlichen Aspekten leiden, welche früher oder später in größerer Unzufriedenheit und Konflikten zwischen den Partnern münden können. Ein sehr großes Problem, welches in der heutigen Gesellschaft viel zu wenig Beachtung findet, auch wenn sehr viele Männer von diesem betroffen sind und mit […]

Unsere Vorgehensweise Nattokinase wird schon seit hunderten von Jahren als Volksheilmittel bei Erkrankungen des Herzens und der Blutgefäße eingesetzt. Nattokinase ist jedoch nur in Sojaprodukten als Natto zu finden, da es durch einen speziellen Fermentationsprozess produziert wird. Nattokinase wird häufig oral bei kardiovaskulären Erkrankungen wie Herzerkrankungen, Bluthochdruck, hohem Cholesterinspiegel, Arterienerkrankung und einigen weiteren Beschwerden eingesetzt […]

Unsere Vorgehensweise Probiotische Pillen sind Nahrungsergänzungsmittel, die die Gesundheit der Verdauung, das Immunsystem und die Energie verbessern und sogar die Gewichtsabnahme fördern können. Aber bei der großen Auswahl an probiotischen Nahrungsergänzungsmitteln auf dem Markt kann sich die Wahl des richtigen Probiotikums für deine Bedürfnisse wie eine entmutigende Aufgabe anfühlen. Um dir zu helfen, das beste […]

Unsere Vorgehensweise Du denkst, du brauchst keinen Sonnenschirm? Wenn nicht, liegst du falsch. Viele Menschen leiden unter anhaltenden allgemeinen Symptomen wie Müdigkeit, Schmerzen, Verdauungsstörungen oder allgemeiner Reizbarkeit, die nicht auf eine echte Krankheit zurückgeführt werden können. Die Menschen akzeptieren die Symptome und versuchen bestenfalls, sie zu bekämpfen. Das hilft ihnen aber auf Dauer nicht, denn […]
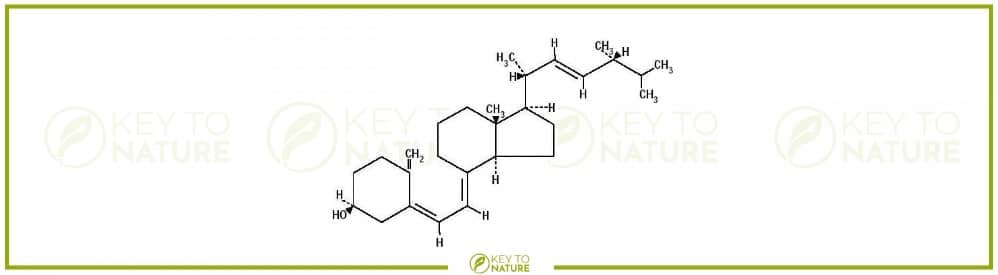
Unsere Vorgehensweise Zwei der wohl wichtigsten Vitamine, welche eine tragende und fundamentale Rolle in dem menschlichen Organismus spielen, sind die beiden Vitamine D3 und K2. Diese erfreuen sich nicht nur einzeln, sondern vor allem auch in der Kombination einer großen Beliebtheit, sodass viele Anbieter des Marktes der Nahrungsergänzungsmittel verschiedene Präparate anbieten, welche sich aus den […]

Unsere Vorgehensweise Im menschlichen Organismus spielen sich jeden Tag viele unterschiedliche Prozesse ab. Damit diese einwandfrei ablaufen und dazu beitragen, dass unser Körper samt all seiner Funktionen funktioniert, ist es wichtig, dass die Nährstoffspeicher mit den entsprechenden wichtigen Nährstoffen gefüllt sind. Einige der Nährstoffe kann der Körper über die Nahrung aufnehmen, andere kann er selbst […]

Unsere Vorgehensweise Für das männliche Selbstbewusstsein im Bett und auch im Allgemeinen spielt die Länge des Penis eine essenzielle Rolle. Leider ist es in diesem Zusammenhang keine Seltenheit, dass Männer mit der Länger und auch mit dem Durchmesser ihrem Glied unzufrieden und aus diesem Grund nach Mitteln und Möglichkeiten sind, um ihren Penis in der […]

Unsere Vorgehensweise Ob ein Mann selbstbewusst im Bett ist und seinen Geschlechtspartner beim Sex befriedigen kann, ist unter anderem immer auch eine Frage der Länge und des Durchmessers des Penis. Doch nicht nur die Größe des Penis hat einen großen Einfluss auf die Befriedigung des Partners und das Selbstbewusstsein des Mannes, sondern auch die Erektionsfähigkeit […]

Unsere Vorgehensweise Das männliche Geschlechtsorgan ist ein Bereich des Körpers, mit welchem viele Männer unzufrieden ist. Entweder ist der Penis zu klein oder im Umfang nicht dick genug, was dazu führt, dass das Selbstbewusstsein der Betroffenen sehr stark unter der Annahme leidet, einen zu kleinen und zu dünnen Penis zu haben. Obwohl viele Männer denken, […]